
What is GraphQL?
GraphQL is a cool kid on the block when it comes to API development. So what is so special about it?

GraphQL is a query language for your API. It is also backed by a run time to fulfil the queries on the server. GraphQL is a specification, a blueprint and there are various implementations of GraphQL across various different programming languages.
GraphQL is an application layer, it does not concern itself about where the data is stored. Your data can be stored in a database or can even come from a third party REST API service. GraphQL is all about getting your queries and serving back a response, usually JSON, which mirrors the query.
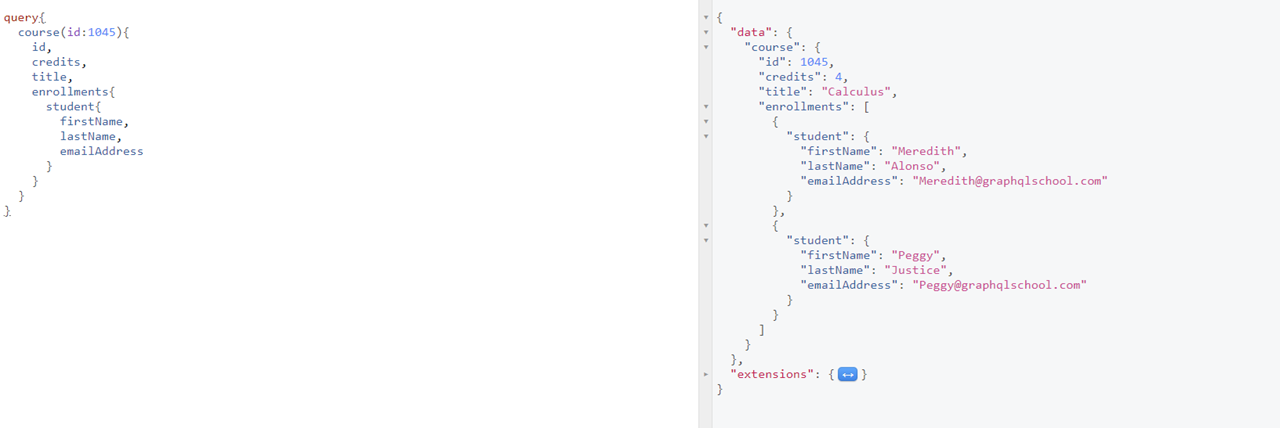
In the above screenshot, I am asking for the details about a course with id 1045 and asking for some fields on it. I can even ask for related data but the response mirrors the query. Data, in general, can often be defined as a graph of relationships between various objects and GraphQL. GraphQL lets you traverse the data graph and extract parts of it.
GraphQL at its simplest definition is all about types and fields. You specify types and ask for specific fields on the types. At the heart of a GraphQL API is a strongly typed system called schema that defines the hierarchy of types. There are 4 main types - object types, which represent the objects that can be queried and operation types that let you act on these objects. There are 3 operation types in GraphQL - query, for reading data, mutations for inserts, updates and deletes, and subscriptions, for pushed updates. The types are made up of fields and each field can be queried. A field has a name, the name used to ask for it, a type, a type like an int, string or even another object type which its resolves to, and a resolver that help to resolve the data from the data store.
With a GraphQL API you typically have only one endpoint that receives mutations, subscriptions or query operations as GraphQL queries and the API does the work and returns the response.
How did GraphQL come into existence?
GraphQL was developed by Facebook in 2012 as the solution to their heavily criticised mobile app back in 2012. When Facebook created their first mobile app, it was making a multitude of REST API calls to present the user data. A huge amount of data was going back and forth between the app and the server thus depleting the user of both their network bandwidth as well as the device battery. Primarily there was two scenarios:
Over fetching - The client app does not have everything that it needs so makes a million API calls, uses up what is needed and throws away the rest.
Under fetching - At no point does the client app has all the information that it needs. This in turn leads to more API calls resulting in over fetching.
This continues in a vicious circle, on and on. GraphQL was the answer that the Facebook engineers came up with, which helps the client ask for what they need and the API responds by giving nothing more than what has been asked for. In other words, exact fetching. This also means that the client and server are loosely coupled and this aids in rapid development and iterations of the server and client at their own pace.
Yay GraphQL
Let me talk about where GraphQL wins.
- Strongly Typed - GraphQL has a strongly-typed schema at it's centre
- Introspective - GraphQL can query itself and this feature helps with auto-generating documentation for the API
- Hierarchical - GraphQL respects the relationships between the objects in your data graph
- Version Free - GraphQL APIs are version free. Fields can be added without affecting clients, who doesn't know about these fields until they use it. If you want to remove fields, they can be marked as deprecated and subsequently removed.
- Exact fetching of data - This results in less round trips and less network bandwidth usage
- Loosely coupled client and server - Client controls what they need and due to the exact fetching nature of GraphQL, this results in a loosely coupled architecture.
Nay GraphQL
GraphQL is not without any cons.
- Caching - With a single endpoint, it's not really possible to implement caching. Although there are workarounds, caching is not something that is specified as a part of the specification.
- File Uploads - Again, this can be tricky. Its not a part of the specification. You can Base-64 encode and send the file as a stream but this can result in heavy network usage.
Resources
- Learn GraphQL
- Learn GraphQL Basics
- GraphQL DotNet
- HotChocolate
- Introduction to GraphQL(video series)
- Building Real-time Applications with Blazor and GraphQL
- Demo Repo - Creating a GraphQL API in .NET Core and consuming it in a Blazor WASM app

