
REST, gRPC and GraphQL - Part 1 - The basics
I am speaking at Build Stuff 2023 next week and my session is "REST, gRPC & GraphQL - A Comparison". This article is a supporting resource for my session.

Before you start reading, I also wrote similar content for the JetBrains .NET Annotated Weekly in April 2023 which can be read here. It contains some additional information that I don't cover here.
Talk about APIs, they are everywhere! From ordering your favourite Friday night takeaway to booking your airline ticket, APIs are in play. They are the connecting bridges that help systems communicate with each other. When we think of APIs there are 3 major API paradigms out there - REST, gRPC and GraphQL. But that's where the similarities between them start and end! The three paradigms are so different, with their own pros and cons, use cases and so on! So let us understand the basics about each in this post.
gRPC
gRPC is a modern, high-performance, open-source Remote Procedure Call (RPC) Framework. RPC frameworks are not a new thing. They date back to 1970s/1980s. But gRPC is fairly new. gRPC is Google's implementation of RPC. It was initially called Project Stubby. In 2015, it was made open-source and called gRPC.
RPC frameworks specialise in location transparency. As the name suggests, Remote Procedure Call is all about calling a procedure remotely. However, the procedure call is programmed in such a way that it looks like a local function call to the client. But in reality, it jumps the network and executes on the server. Invoking procedures or functions on another computer as though a local function call is the essence of RPC. gRPC is no different.
The key feature of gRPC is functions/procedures/methods.
gRPC is designed for HTTP/2 and beyond. It favours contract-based API development and is supported across various different programming languages. gRPC is the recommended framework for RPC requirements in the .NET world which started supporting gRPC from .NET Core 3.0 onwards.
Protocol Buffers
Protocol Buffers are the interface definition language(IDL) and message exchange format with gRPC. It's Google's mechanism to serialize structured data. Protocol Buffers are language-neutral, platform-neutral and extensible.
Messages
Data for message exchange(requests and responses) are structured as messages with gRPC. Think of JSON, but faster, smaller and more performant. Messages are made up of key-value pairs called fields. Messages are transmitted in binary format. 
Note: Unlike JSON where the value of each field is serialized against the name of the field, here it is serialized against the unique number against each field. This further adds to the reduction in the size of the message format for transmission.
Proto files
The contract of a gRPC service is specified in proto files, files with .proto extension. Each proto file typically defines a service, rpc definitions (procedures), messages (requests and responses)
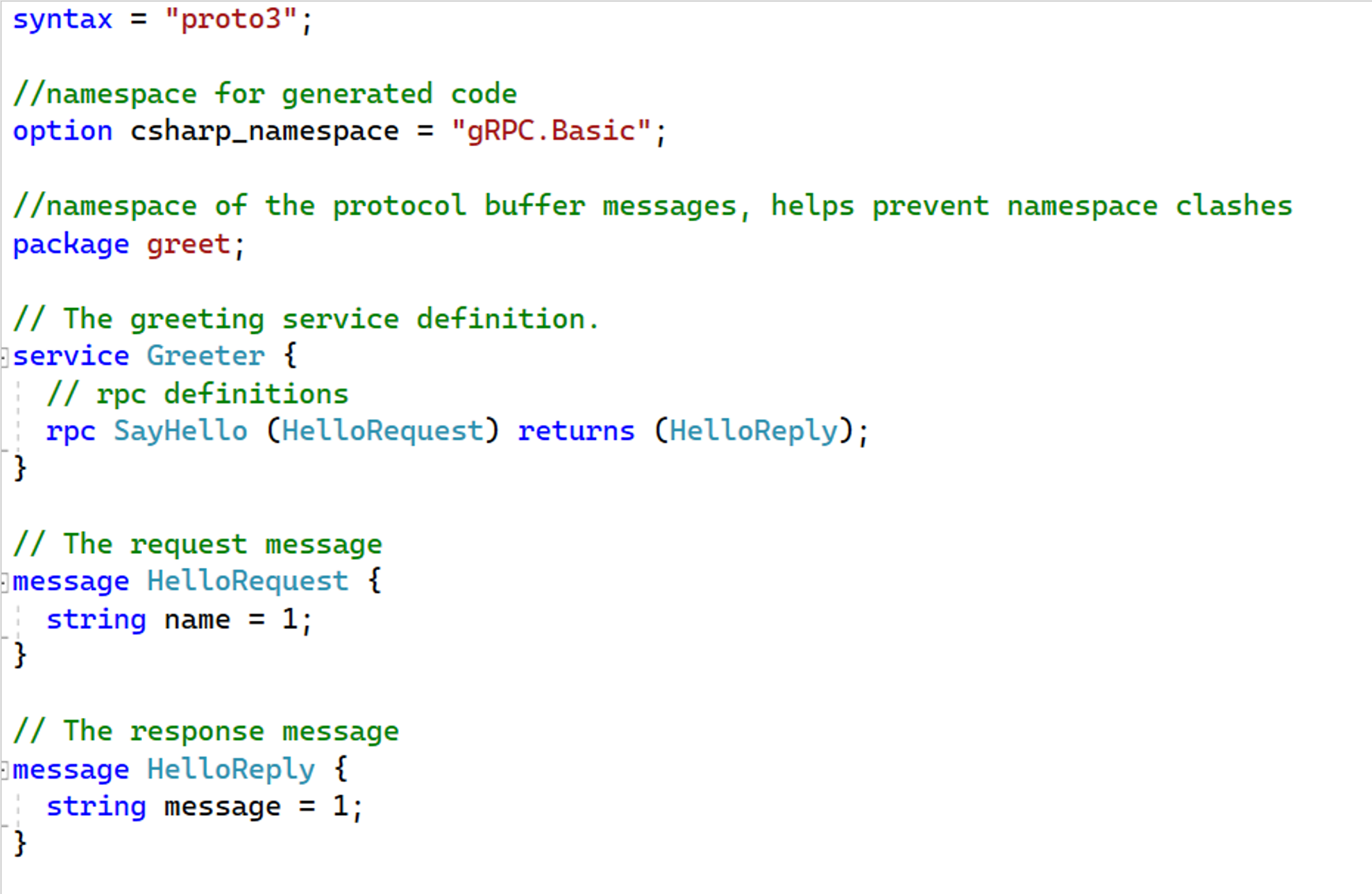
The protoc compiler acts on these proto files to generate server-side and client-side code. The server-side code is usually extended to give the various rpc definitions your own implementation. The client apps that consume your service should use the generated client-side code to communicate with your service. So sharing the proto file is key. They need to be made available for your clients to generate code to consume your service.
The protoc compiler, by default, understands a huge list of languages and can generate code following the conventions and standards for these languages. The protoc compiler together with the protocol buffers makes gRPC a befitting candidate for polyglot systems.
REST
REST stands for Representational State Transfer. It was presented by Roy Fielding in his famous dissertation in 2000, as a means to standardise web. It is an architectural style for distributed systems, like the web, that provides you guidelines on how to make your system REST-ful, but leaves the implementation to you. REST is THE most widely adopted API pattern. So much so that every time we develop an API that can communicate over HTTP and give you JSON/XML responses, we term it REST API. That is far from the truth though as you will read below.
REST is based on resources. The key feature is a resource, anything that can have a computer representation - a car, a user, a pomegranate, all are resources. REST is all about thinking in terms of resources, collection of resources, acting upon them or even modelling them. Each resource has a unique resource identifier. In case of an API it is usually a URL (Uniform Resource Locator).
When a client communicates with your API, a resource representation is used. A resource representation is made up of data, metadata and hypermedia. It is used to change state.
The server manipulates the application state on the client by issuing a new resource representation. Similarly, the client can change the resource state on the server by issuing a new resource representation. This manipulation of state or using resource representation to transfer state is the key concept behind Representational State Transfer.
Rest Constraints / Fielding Constraints
REST is driven by 6 constraints that describe the REST-ful architectural style
- Client-server - The client asks for information and the server should provide that information in an uninterrupted manner
- Stateless - Every request from the client must contain everything for the server to fulfil that request. Fulfilling a request must not be reliant on any request that came before or after a request. Session state etc must be stored on intermediaries
- Cacheable - There should be an ability to cache responses and use them as the response for further equivalent requests
- Uniform Interface - This is further divided into 4 sub constraints
- Identification of resource - Each resource must be identifiable using a unique identifier
- Manipulation of resource - Resources can be manipulated or represented using multiple formats like JSON, XML, Text, HTML
- Self-descriptive messages - Each message must be complete in itself
- HATEOAS - Connectedness or browseability. What state can the client go into? The answer to this question is provided by HATEOAS
- Layered Systems - A REST-ful system can be comprised of multiple layers, with each layer communicating to the layer immediately above and below it. Layers can be added or removed or updated. The layers provide transparency and a client must not be aware of whether it is sending the request to a proxy, or server or gateway.
- Code on demand - An optional constraint that says code/executables can be served as a response
Any system that adheres to these constraints can be considered a REST-ful system.
HATEOAS
HATEOAS stands for Hypermedia as the Engine of Application State. This is the most important concept in REST and what makes a system completely REST-ful. Imagine a server that serves up a web page. The potential next steps the client can take, i.e. the new pages it can browse to are served back with the response from the server rather than being hardcoded on the client. This is HATEOAS in a nutshell. The client should be able to make decisions on what state it can achieve from the responses served by the server.
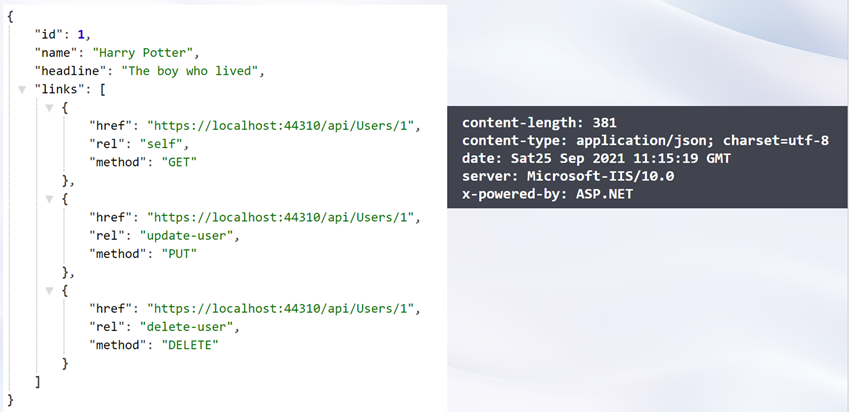
With regards to an API this “what can you do next” information typically is in the form of how can you create, update or delete a resource, what are the related resources etc. And the information to get to this “application state” is served up as a series of links in the response. Helping clients achieve a new application state by using hypermedia as the engine is the definition of HATEOAS. A typical response with hypermedia can look as shown below
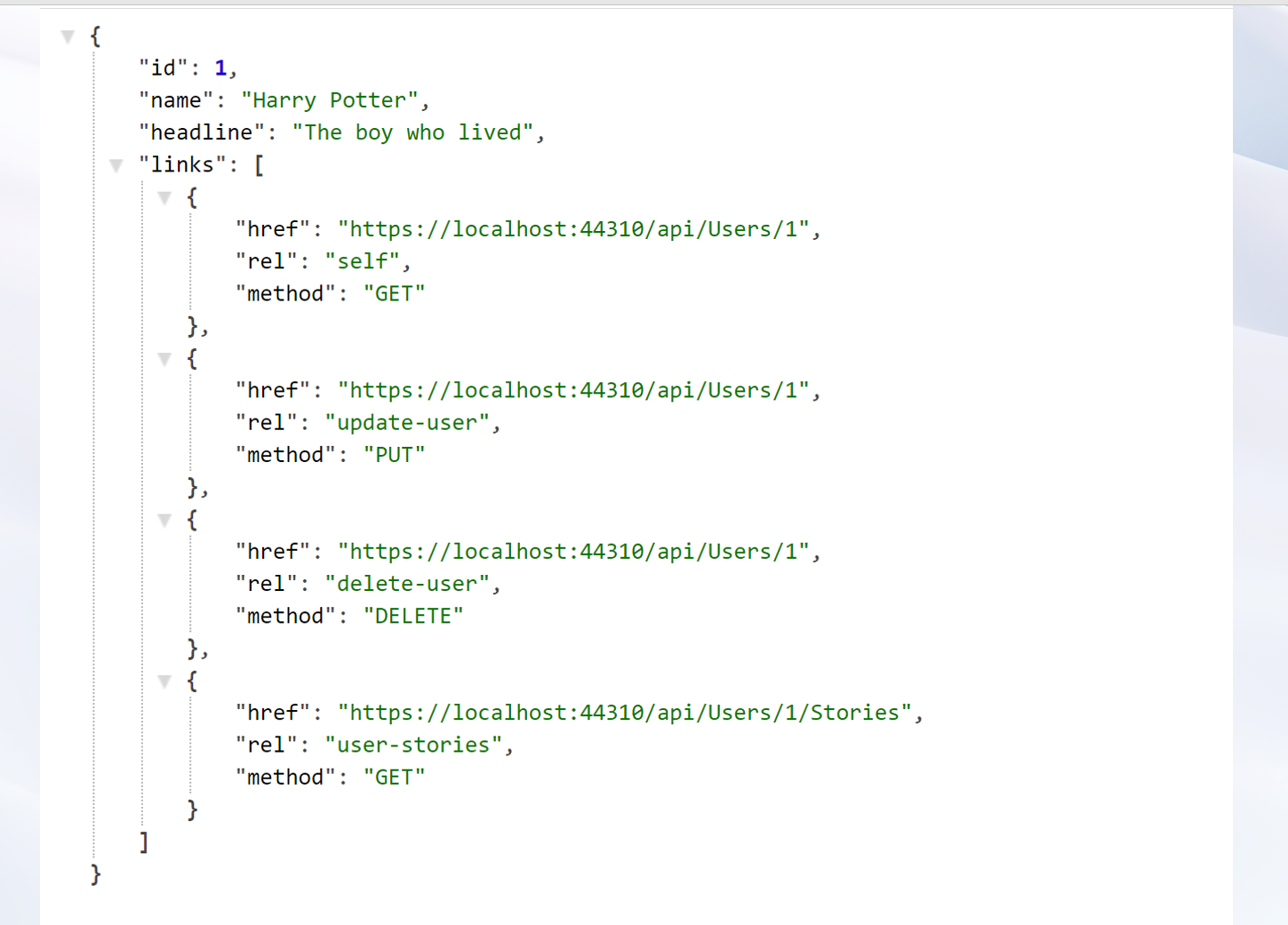
According to Richardson Maturity Model, it is when you have implemented HATEOAS, is your system truly REST-ful. HATEOAS is the factor which completely decouples the client and server.
GraphQL
GraphQL is an API paradigm like no other. Because it's not an API, it's a query language for your API that is supported by a server-side runtime that understands, parses and understands these queries.
GraphQL came into the picture in 2012-2013 period when Facebook was slammed for their mobile app that drained bandwidth and battery of the devices. The culprit was the REST API they were using to present the user with a News Feed on the app. For every user, the app had to get the user information, use a part of it and discard the rest. For every news item in the feed, it had to get the news item to use some details like the basic details of the item and discard the rest. The news item only gave an id for the user, so for each news item it had to fetch details of the user. Furthermore, for each comment to the story, it had to get the comment and also user details. So as you can clearly see, it was getting cumulative. It looks like a ton of calls were made to form that news feed. And the API being REST-based served a fixed response and given the news feed, only a part of it was used. However, the information received was not enough at any point, like in the case of the user associated with a news item, so it fetched more data. There was overfetching - getting more data than required, using some and discarding the rest, and underfetching - at no point I have all the data that I needed, which in turn resulted in overfetching. There was also the N+1 problem on the client. All this was because REST is resource-based and Facebook engineers figured out that the situation demanded something more flexible, something where the client decides what they want and the API serves up just what is being asked for and that was a new technology - GraphQL.
GraphQL is a very client-focussed, experience-driven API. The client asks for what they want and they get exactly what they asked for, nothing more nothing less. If you look at the screenshot below, you can see that! Furthermore, the shape of the data returned is predictable, as it is a mirror image of your JSON-ish query!
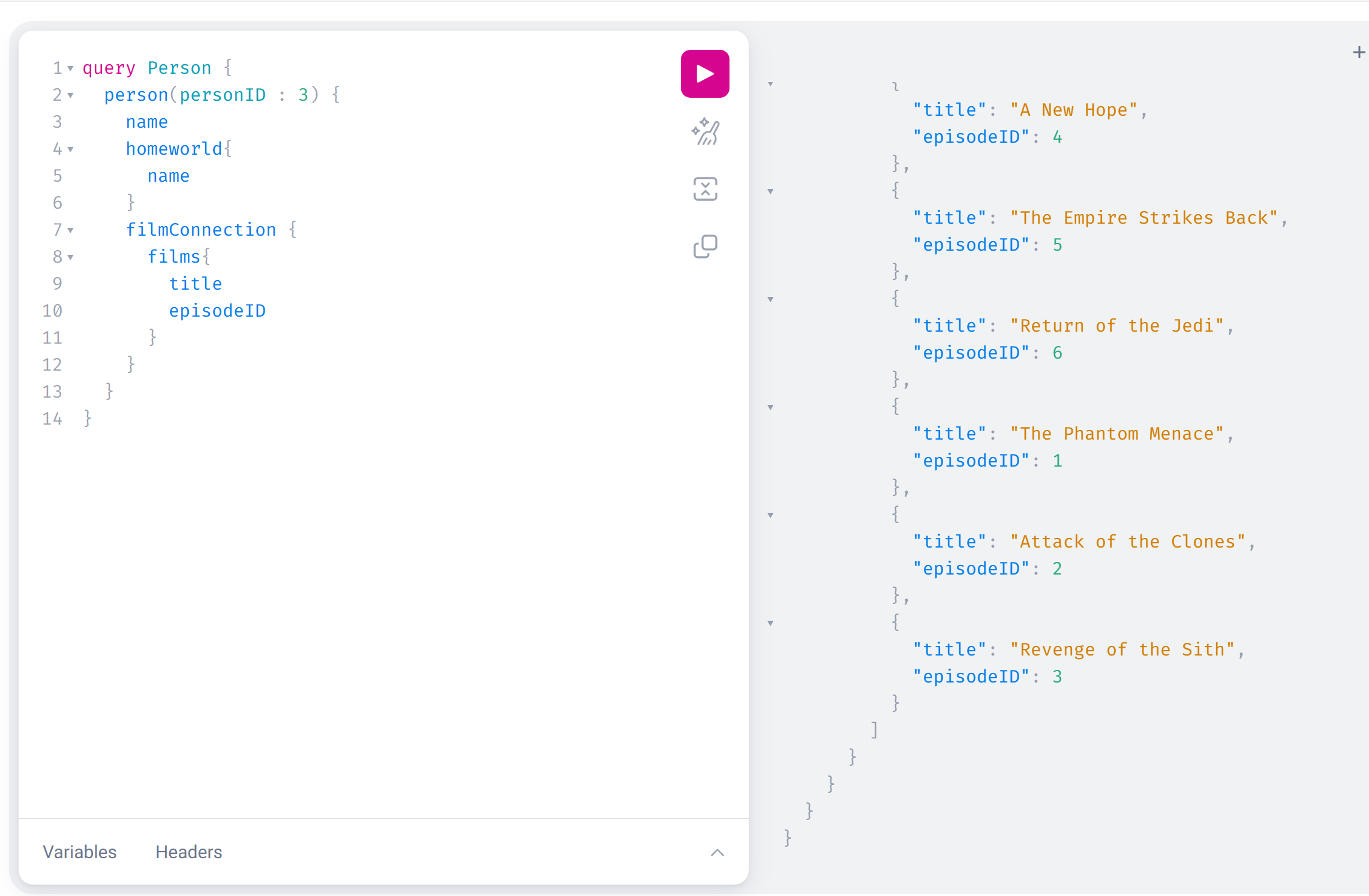
Note : I used https://graphql.org/swapi-graphql for this!
GraphQL is all about giving your data the shape that you asked for. It does not worry about where the data is stored. It can be in a database, another API or even multiple other GraphQL endpoints. It's like an application layer that comes in between you and your data. So it can also be called GraphQL server. GraphQL understands your entities and respects the hierarchy. It visualises the relationship between your objects as a graph and helps you extract parts of it, hence the name GraphQL.
But how does the server understand your queries? Because how a GraphQL server should be implemented is a specification! You don't need to worry about it because there are several implementations of GraphQL in various different programming languages.
If you want to read more about GraphQL I have got some reads for you here!

