GraphQL & Azure Functions - Part 1
In this article series, we will look at implementing GraphQL with Azure Functions.

GraphqL is one of the very popular API patterns which enjoys gaining popularity these days. When I talk about GraphQL I often refer to it as a cool kid on the API block. It is a very different API paradigm, unlike REST or gRPC. GraphQL is a query language for your API that is backed by a runtime that is capable of understanding, parsing, and executing those queries. GraphQL is an application layer, that sits on top of your existing data. So your data can be in a database, a REST API, or even another GraphQL API or a collection of them. GraphQL doesn't concern itself with where the data is stored, it is all about giving you the data in the shape and form that you asked for! It is essentially an interface between your app and back-end hence GraphQL APIs are sometimes termed GraphQL servers.
Why GraphQL?
GraphQL was introduced by Facebook in 2012 and since then it has been adopted by some very big names like Netflix, GitHub, and Shopify. But to reiterate the history of how it all happened, it all started with the Facebook app back in 2012. The app was heavily criticised for its very slow start-up, and heavy data usage leading to drainage of the device battery. Not good at all!! Back then the app was using the exact same tech stack as the Facebook web app which was identified as a reason for the poor performance of the app. One of the major causes of trouble was the REST API that was powering the app, particularly the news feed.
The scenario went like this or something along the lines of this. Upon login, the app was reaching out to the REST API to get my information which is fine. The object returned was a big one, that contained everything about my profile which is fine too. But the mobile app has a very different viewport compared to the web app which meant that I was using a fraction of what was fetched (userid, profile image, name alone) and discarding the rest. This is called over fetching. This was quite unaffordable for the data packages on devices in those days.
Another issue was with the newsfeed. The REST API would get the news feed from the user id obtained above. But in the news feed, there would be ids for the author of the story or the comments or likes which would need another REST API call to convert to actual data. Multiply it by the number of items in the news feed, it is a massive number of calls. Not to add here again that what actually might be used in the app could be way less than the amount of data returned. This multitude of calls(called under fetching, which goes hand-in-hand and leads to over fetching) and wastage of data cumulatively dragged down the performance of the mobile app. Facebook engineers decided that they needed to shift the responsibility from the resource-focused REST API that says I will give you what I have to something more client-centric that said Tell me what you want and I will get you that! GraphQL was the answer.
What is GraphQL?
GraphQL is a query language for your API that is backed by a runtime that is capable of understanding, parsing, and executing those queries. To put it in simpler English, you define types and ask for fields on those types. What makes GraphQL stand out is the way it shifts the control of what is being sought to the consuming app than the server itself. Say, if I want to get information about a person, I have to specify what information I want. I can't simply say get me everything. I have to ask for specifics like the id, name, etc. And the server will fetch me just what I asked for and nothing else! No data wasted at all! Furthermore, what we get back from the server is JSON in the same shape as the query, making it predictable for the developers to work with.

You can even ask for related information in a single call, and that would be given to you by the server thereby avoiding the need for roundtrips to the server.
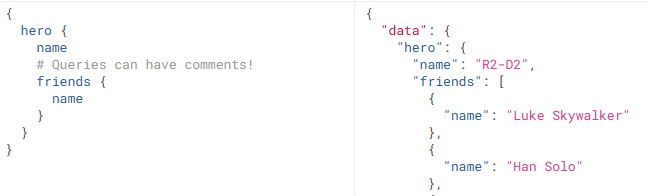
In the REST world, this would be 3 calls - one to get the hero and then two calls to get friend names(one each for each friend id, We have the N+1 problem kicking in here as well with REST).
Examples from Queries and Mutations | GraphQL
GraphQL is backed by a type system called schema. The schema defines all the types and the complete set of data that you can possibly get from the service. Queries are validated and executed against the schema. GraphQL schema is not responsible for where the data comes from, it helps define the shape of the data graph and establish relationships between objects.
The most important terms to understand about a schema are
- Object Types - the kind of objects that can be fetched from the API. For e.g, a Person type
- Query - The root operation type which represents a side-effect free, read operation
- Mutation - The root operation type to change(insert/update/delate) data, typically a change followed by a fetch
- Subscription - Real-time capabilities, which enables clients to subscribe to events and recieve a stream of data from the server.
While mutations and subscriptions are totally optional, having queries and object types is compulsory.
Types are made up of fields. Be it object types or operation types, they are made up of fields. Each field has a name, a type (scalar/object type) it resolves to, and a resolver that resolves the field to concrete data.
GraphQL is a specification which means various programming languages have implementations of GraphQL. With .NET, there are 2 implementations of GraphQL both of which are open-source projects.
- GraphQL for .NET
- Hot Chocolate
We will use Hot Chocolate to implement an API, but I am taking it a level further by using Azure Functions rather than a standalone ASP.NET Core Server. This means my GraphQL server runs as an Azure Function.
Azure Functions and GraphQL - Benefits
Azure Functions leads the product range in Azure when it comes to serverless computing. With serverless, there are servers, but developers don't need to do any work to provision, manage, or even scale them. These tasks are invisible to the developer, which means they can focus on the application logic and not worry about the resources.
GraphQL is an application layer that gets data from your data source or even aggregates data from multiple sources. Furthermore, the client-centric nature of GraphQL means the client and server can iterate at their own pace, reducing the coupling. With Azure Functions, developers can focus on the application logic, and iterate at a rapid pace. Organizations can control cost (starting with pay for usage) while offloading the scaling responsibility without any compromise to availability. Furthermore, GraphQL on Azure Functions acts as that lightweight application layer that exposes your business layer while separating the concerns. With each layer doing what they are best at, together with cloud hosting, you can achieve cloud-native architecture for your system where each layer can be scaled and is resilient. This makes Azure Functions a very good choice for GraphQL.
Implementation
We will start off by creating our local development environment. I have set up an Azure Function that runs in isolated worker process mode.
Azure Function - A word about in-process and isolated worker process models
The isolated worker process was introduced in 2021. Azure Functions host is the runtime that powers Azure Functions. Prior to the isolated process, there was only the in-process model in which there was a tight coupling between the function app and the host. Your function app was a .NET class library that would be loaded by the Azure Functions host and runs in the same process as the host. The major trade-off here was that the host and the class library function will have to run the same version of .NET. As a solution to support .NET versions that have a predictable, annual release cadence, it was important for Microsoft that they support these versions from day 1 of release unlike .NET 5 for which Azure Functions support came months later. The reason was them trying to come up with a model using which they could support .NET versions from day 1 and .NET 5 being the first non-LTS version it was the right time for that.
With Azure Functions isolated worker process model, the tight coupling is no longer the story. Your function app is a .NET console app that references a worker SDK. This brings the benefits of
- full control over function start-up
- no conflict of dependencies between functions and host process
- ability to add custom middleware
- Dependency Injection
- Familiar/uniform developer experience
- and, most importantly, the function app could run in a different .NET version than the host
The isolated worker process model seems to be the future for Azure Functions although there is no set timeline as to when the in-process model would be phased out. But if you wish to create an Azure Function in a non-LTS .NET version, you have to use the isolated worker process model.
Further differences can be found in MS Docs.
Implementing queries and mutations
To get started with GraphQL in Azure Functions Isolated Process Mode, we need to install the Nuget Package HotChocolate.AzureFunctions.IsolatedProcess. I am using the version 13.0.0-preview.96
Next, I need to set up my model, which is a very simple Person.cs POCO
public class Person
{
public int Id { get; set; }
public string Name { get; set; }
}This is my object type and has two fields - Id and Name, that can be queried.The Hot Chocolate convention is - all public properties becomes fields and the get accessors becomes resolvers for the fields.
I need a repository to act on my data, so I have a PersonRepository.cs that looks as shown below.
public class PersonRepository
{
private List<Person> people = new List<Person>() {
new Person() { Id = 1, Name = "Poornima" },
new Person() { Id = 2, Name = "Kavya" } };
public Person GetPerson(int id) { return people.FirstOrDefault(p => p.Id == id); }
public List<Person> GetPersons() { return people; }
public Person AddPerson(Person person)
{
people.Add(person);
return person;
}
}Now let us implement a query. With HotChocolate, you can define a regular class with methods as your query. Each method name becomes a field on the query type and the methods are resolvers that resolves the field to concrete data. Prefixes like "Get", and suffixes like "Async" are ignored while forming the field names. My query has two fields - person, that retrieve a person and persons that retrieves all persons. Note that the GetPerson() method accepts an argument, this is resolved from the incoming GraphQL queries as GraphQL queries can have arguments.
public class Query
{
public Person GetPerson(int id, [Service] PersonRepository personRepository) => personRepository.GetPerson(id);
public List<Person> GetPersons([Service] PersonRepository personRepository) { return personRepository.GetPersons(); }
}To set up a mutation, to add a person, we can follow the same pattern as before. Set up a class and specify our methods. My mutation has just one method - to add a person
public class Mutation
{
public async Task<Person> AddPerson(Person person, [Service] PersonRepository personRepository)
{
personRepository.AddPerson(person);
return person;
}
}Note how the PersonRepository has been injected using Resolver injection rather than Constructor injection. Dependencies must never be injected into GraphQL Types using Constructor injection as GraphQL types are singletons and therefore the injected dependency will also become a singleton.
We now have to wire this all up. With the isolated worker process model, we have a Program.cs file where we can control the start-up behaviour. There is a HostBuilder available, using which we can add our GraphQL server and register our query type and mutation type using the AddGraphQLFunction() method. We can also configure services using the ConfigureServices() method. Putting it all together my Program.cs class looks as shown below.
var host = new HostBuilder()
.ConfigureFunctionsWorkerDefaults()
.AddGraphQLFunction(b => b.AddQueryType<Query>().AddMutationType<Mutation>())//GraphQL server and Azure Functions integration set up
.ConfigureServices(s => s.AddSingleton<PersonRepository>())
.Build();
host.Run();
Finally, our function looks as shown below
public class GraphQLFunction
{
private readonly IGraphQLRequestExecutor _executor;
public GraphQLFunction(IGraphQLRequestExecutor executor)
{
_executor = executor;
}
[Function("GraphQLHttpFunction")]
public Task<HttpResponseData> Run([HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = "graphql/{**slug}")] HttpRequestData request)
=> _executor.ExecuteAsync(request);
}The HTTRequestData is forwarded to the IGraphQLRequestExecutor that handles the execution of the GraphQL query.
Now I can run my project and even browse to the function url and it should serve me the browser-based IDE Banana Cake Pop that can help test my queries. The IDE helps be browse the schema, validate and test my queries.
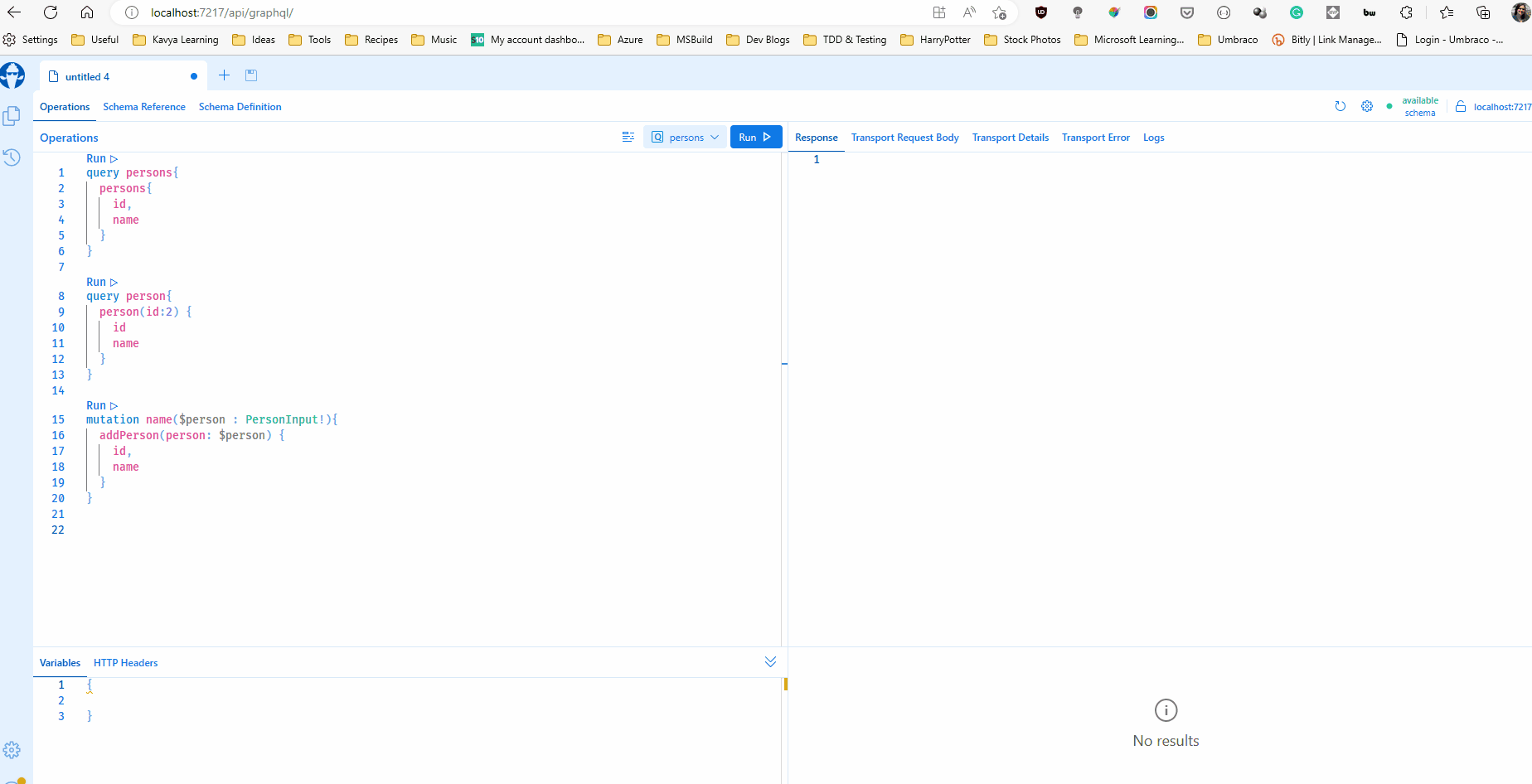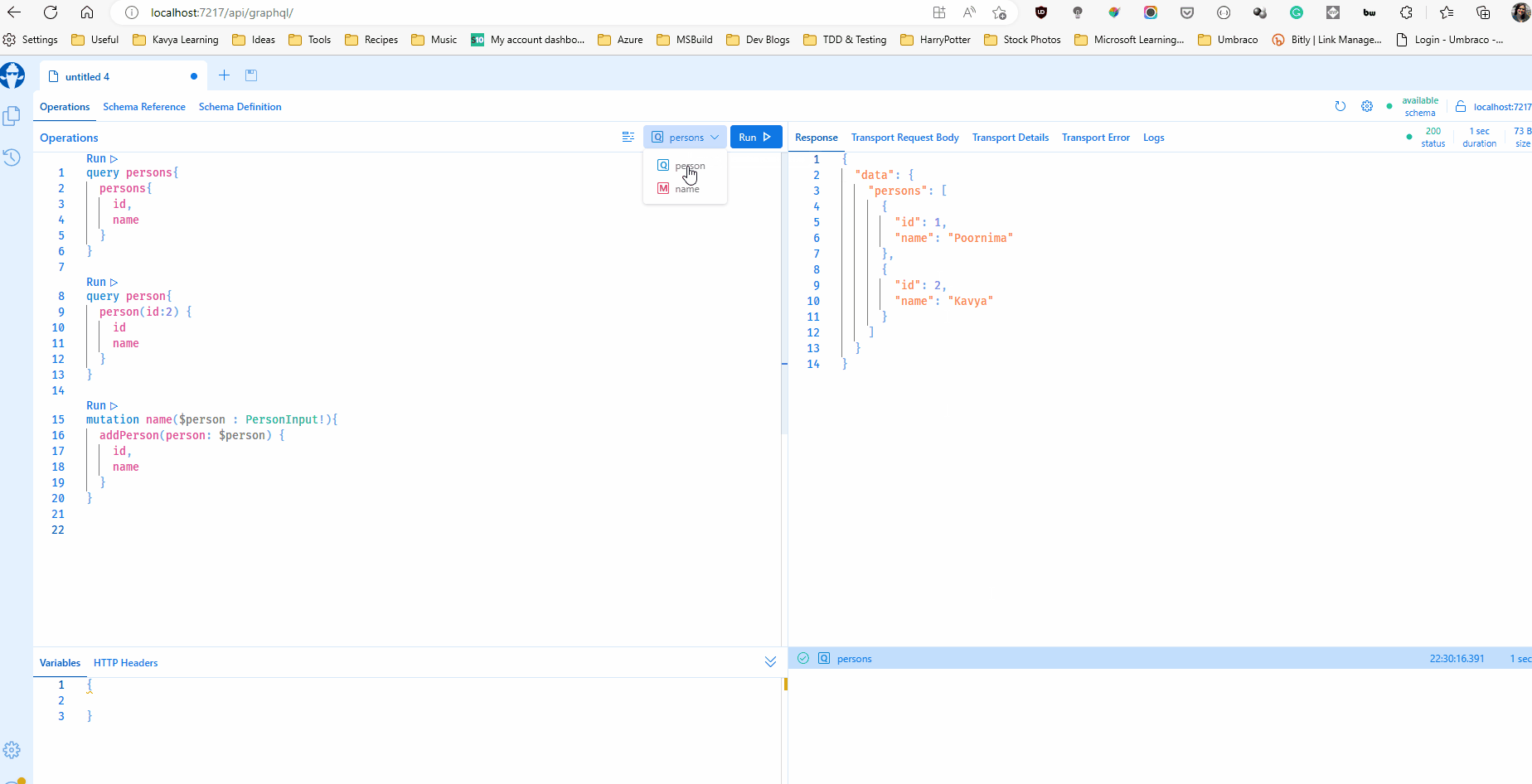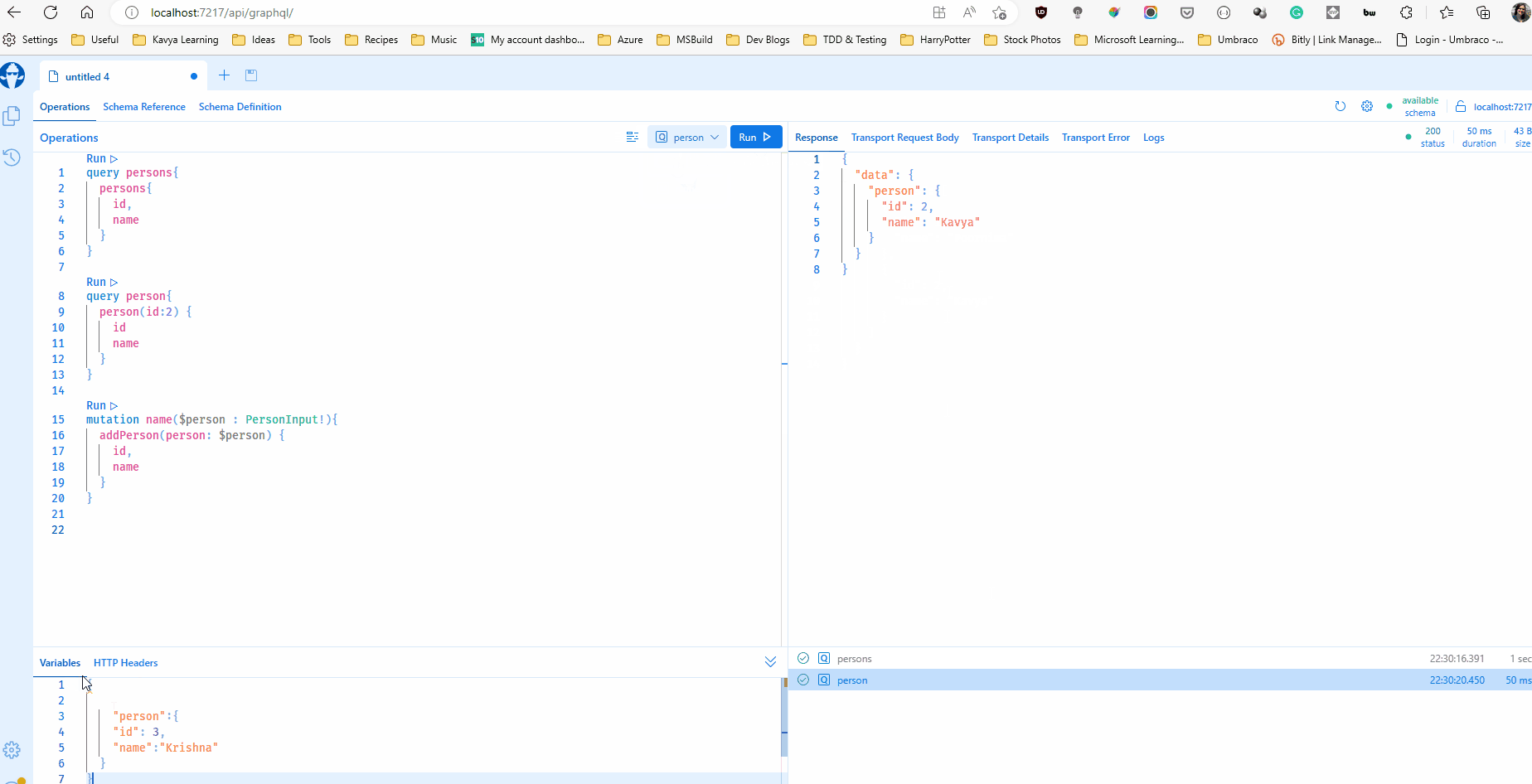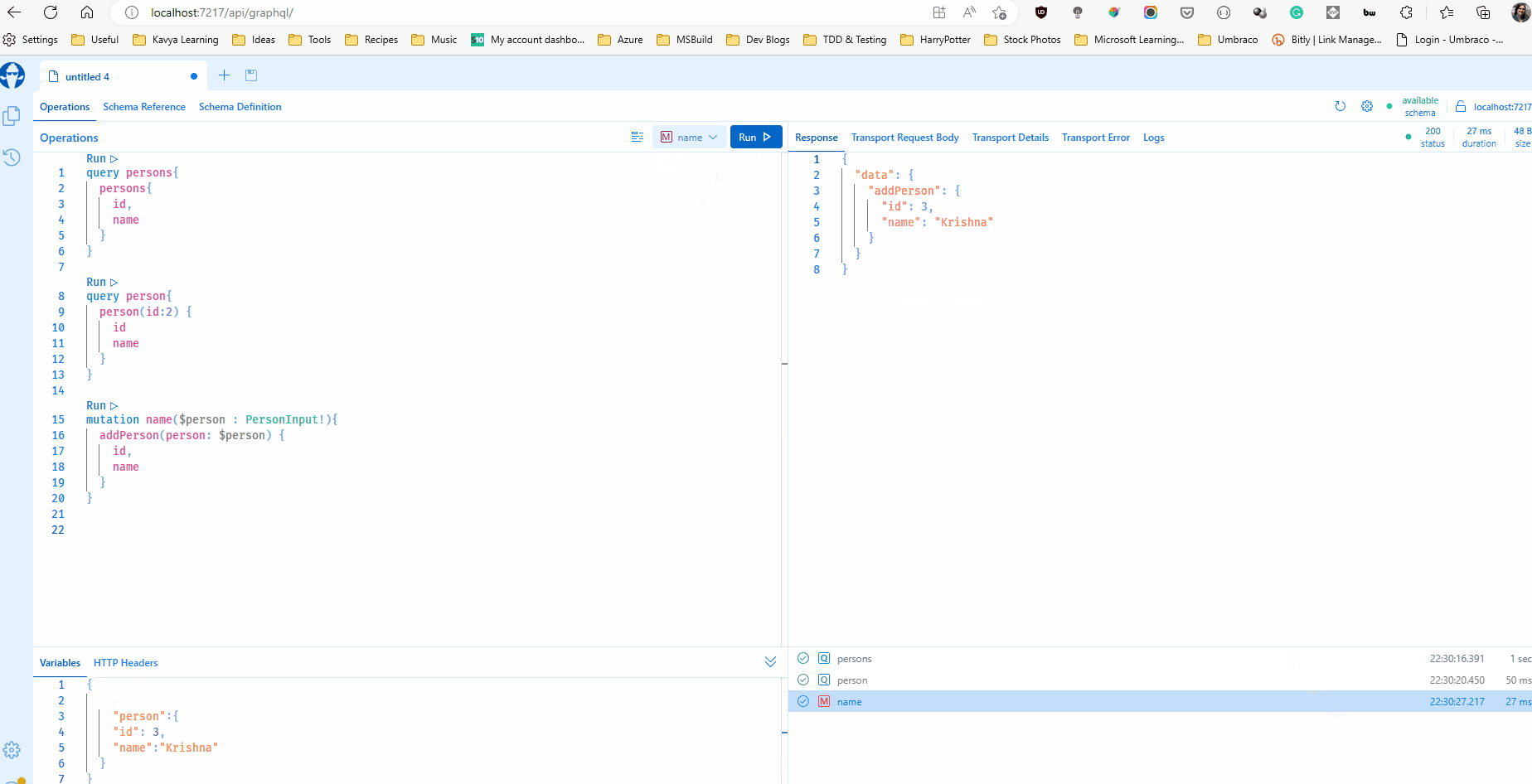

My function allows HTTP GET which makes this possible. But HTTP GET should be turned off in production and Banana Cake Pop must be secured or turned off as well.
Subscriptions are a whole new story with Azure Functions, so we will look at them in Part 2 of this series.